
Attention 正在被越来越广泛地得到应用,尤其是 BERT 火爆之后。Attention 到底有什么特别之处?它的原理和本质是什么?Attention 都有哪些类型?本文将详细讲解 Attention 的方方面面。
Attention 的本质是什么
如果浅层理解,Attention(注意力)机制与其名字非常匹配,其核心逻辑就是从关注全部到关注重点。Attention 机制很像人类看图片的逻辑:当我们看一张图片时,并不看清图片的全部内容,而是将注意力集中在焦点上。
例如,当我们看一张图片时,一定会看清“锦江饭店”这4个字(视觉焦点)

而“电话号码”或“喜运来大酒家”则容易被忽略。

也就是说,我们的视觉系统本质上就是一种 Attention 机制,通过将有限的注意力集中在重点信息上,快速获得最有效的信息。
在 AI 领域,Attention 机制最早应用于计算机视觉,随后在 NLP 领域得到发扬光大。2018 年 BERT 和 GPT 的出色效果使得 Transformer 以及其中的 Attention 核心备受关注。
如果用图来表达 Attention 的位置大致是下面的样子:
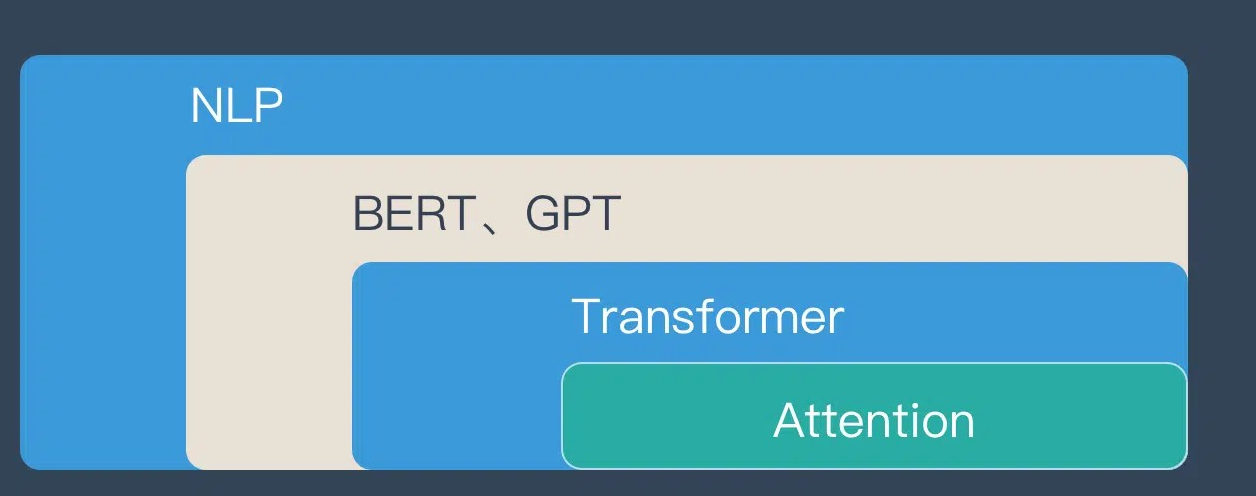
Attention 的3大优点
引入 Attention 机制主要有三个原因:
参数少:与 CNN、RNN 相比,Attention 模型的复杂度更低,参数也更少,对算力要求更小。
速度快:Attention 解决了 RNN 不能并行计算的问题,每一步计算不依赖于上一步结果,因此可以并行处理。
效果好:在 Attention 机制出现之前,长距离信息容易被弱化,就像记忆力差的人记不住过去的事情一样。而 Attention 能够挑选重点,即使文本较长,也能抓住核心信息,不丢失重要内容。【下图示意:红色区域为被挑选出的重点】

Attention 的原理
Attention 常与 Encoder–Decoder 结构联系在一起,用于机器翻译等任务。下面的动图演示了在 Encoder–Decoder 框架下,Attention 如何帮助完成机器翻译任务。
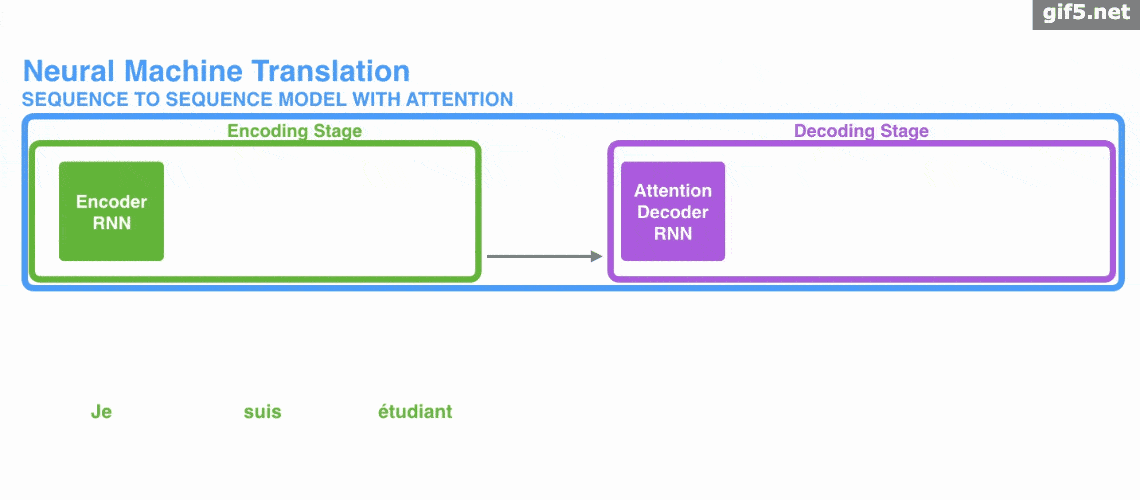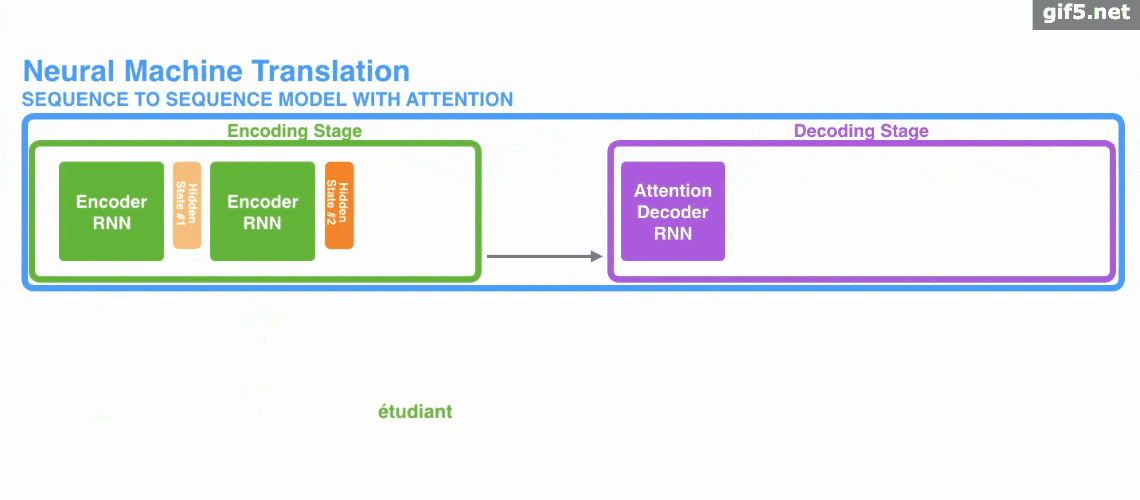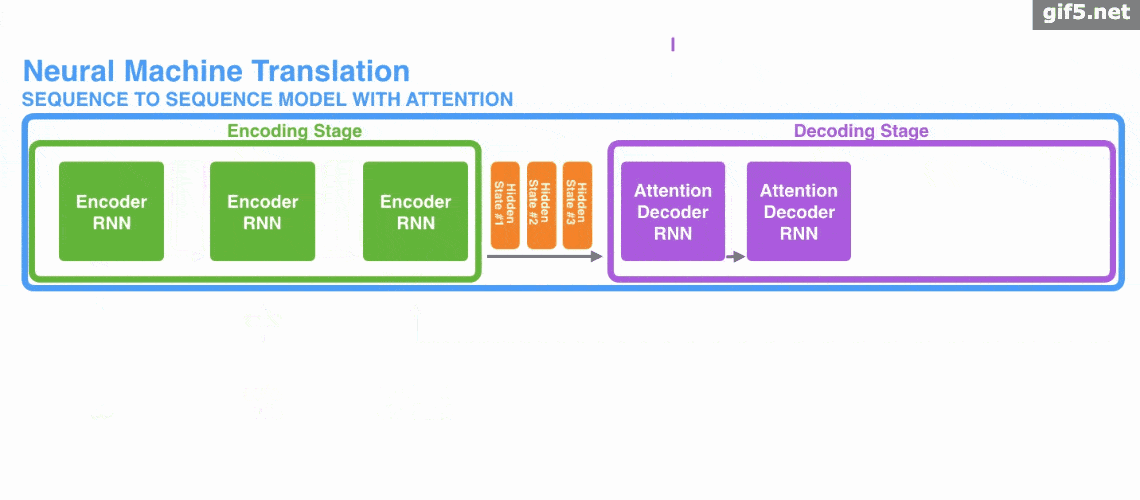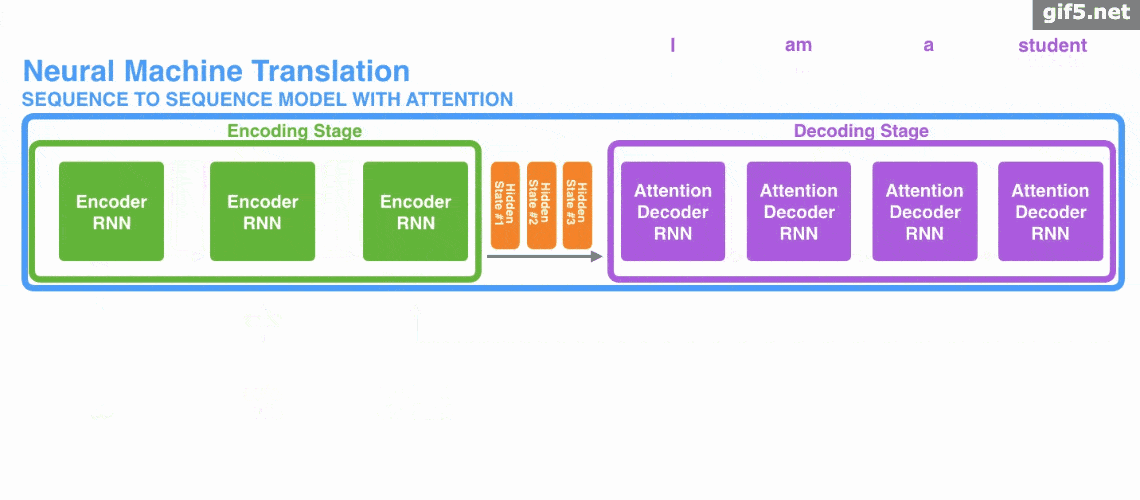
但是,Attention 并不一定要依附于 Encoder–Decoder,它也可以脱离该框架。下图为脱离 Encoder–Decoder 框架后的 Attention 原理图解。
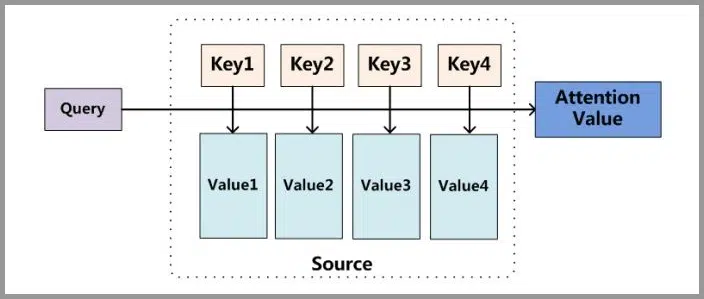
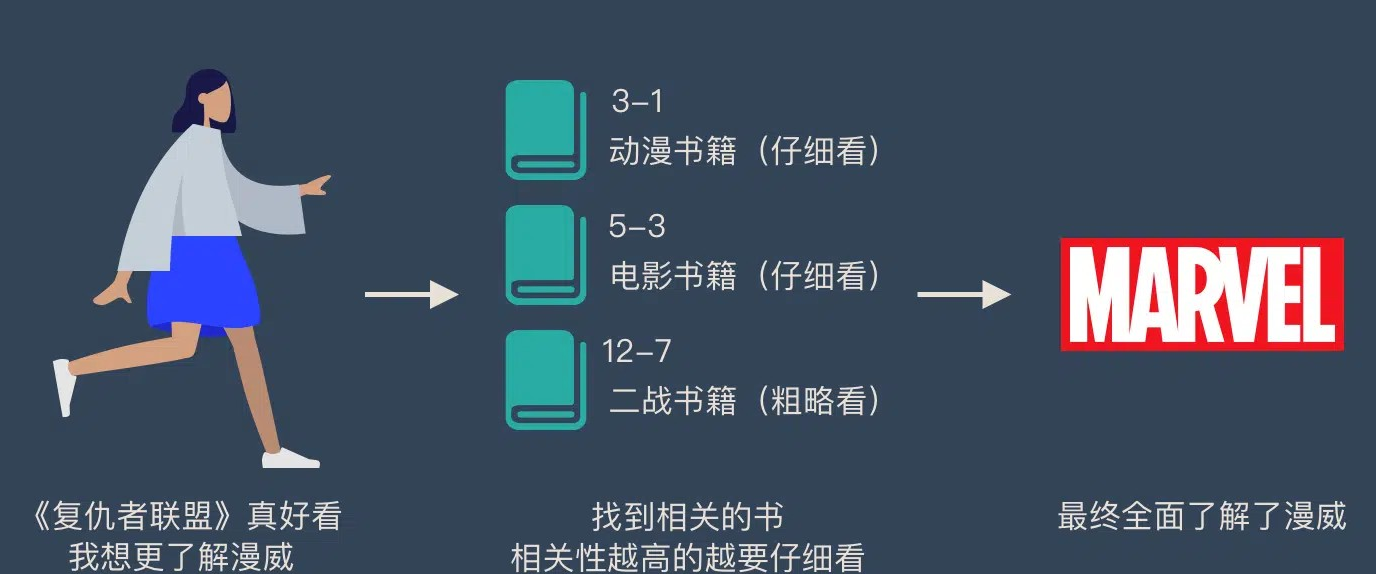
为了更形象地说明 Attention 的原理,我们举一个例子:假设图书馆中有很多书(value),每本书都有编号(key)。当我们想了解“漫威”(query)时,我们会优先关注与动漫、电影相关的书籍(权重高),而与“二战”相关的书籍(权重低)则只需要简单浏览。经过这样的加权,我们最终能对“漫威”有全面了解。
Attention 原理可归纳为3步:
1. Query 与 Key 计算相似度,得到权值;
2. 将权值归一化,得到可用权重;
3. 用权重对 Value 进行加权求和,得到最终输出。
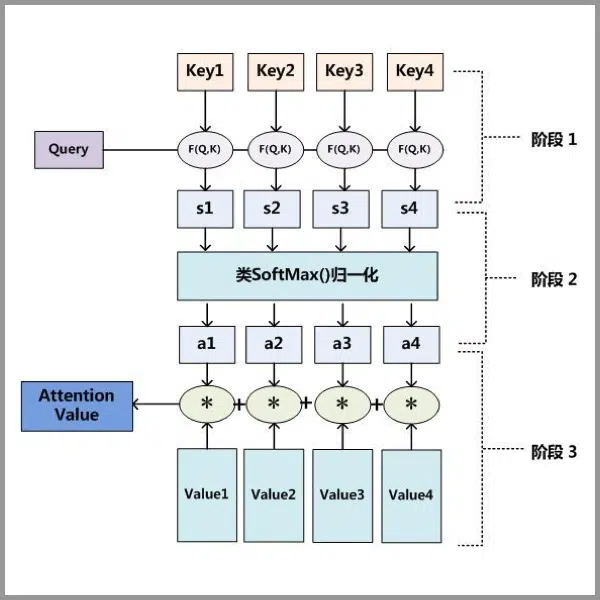
简单来说,Attention 的核心就是“带权求和”,这一机制帮助模型捕捉关键信息。
Attention 的 N 种类型
Attention 有多种不同类型,包括 Soft Attention、Hard Attention、静态 Attention、动态 Attention、Self Attention 等。以下按照不同角度对 Attention 进行归类:

1. 计算区域
• Soft Attention: 对所有 Key 求权重,每个 Key 都有一个对应的权重,属于全局计算(Global Attention)。这种方式参考所有 Key 后进行加权,但计算量较大。
• Hard Attention: 精确定位某个 Key,其余 Key 权重为 0。通常需要强化学习或使用 gumbel softmax 辅助训练,因为其不可导。
• Local Attention: 是 Soft 与 Hard 的折中方案,在一个局部窗口内计算 Attention。
2. 所用信息
• General Attention: 利用外部信息(例如问题向量)与原文本进行对齐;
• Local Attention: 只使用内部信息进行计算,如 Self-Attention,key、value 与 query 均来自输入文本。
3. 结构层次
• 单层 Attention: 用单个 Query 对文本进行一次 Attention;
• 多层 Attention: 先对每个句子计算 Attention 得到句向量,再对所有句向量计算 Attention 得到文档向量;
• 多头 Attention: 使用多个 Query 分别计算 Attention,每个 Query 关注文本不同部分,最后拼接结果。
4. 模型方面
• CNN + Attention: 可在卷积操作前、后或 pooling 层加入 Attention;
• LSTM + Attention: 在 LSTM 上结合 Attention 提升长文本建模效果;
• 纯 Attention: 如 Transformer 中的多头 Attention,不依赖于 CNN 或 RNN。
5. 相似度计算方式
常用方法包括:点乘、矩阵相乘、cos 相似度、串联方式以及使用多层感知机进行计算。
想了解更多技术细节,请参考相关文章和视频资料,如 Transformer 的讲解。
发表评论